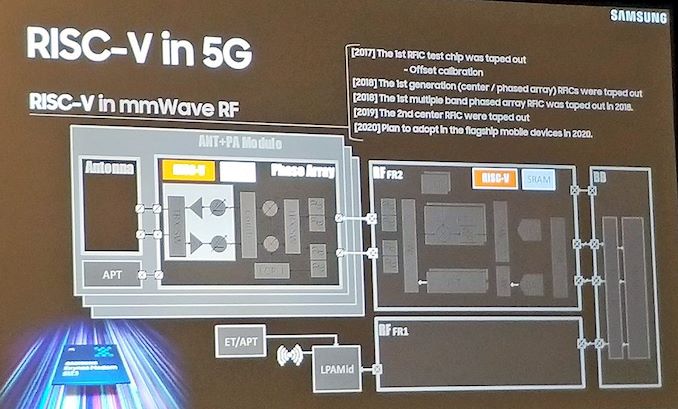
La compétition dans les centres informatiques pour le matériel réseau n’est pas neuve. Autrefois, elle portait sur les capacités techniques du matériel ; désormais, avec l’avènement de l’informatique en nuage, le coût devient plus plus important. Broadcom vient de lancer sa première puce pour la commutation dans les réseaux Ethernet avec une capacité de commutation maximale de plus de vingt-cinq térabits par seconde, baptisée Tomahawk 4.
Celle-ci peut monter à soixante-quatre ports Ethernet à quatre cents gigabits chacun (en faisant la somme, on tombe sur vingt-cinq térabits et six cent gigabits par seconde) ou deux cent cinquante-six ports à seulement cent gigabits par seconde chacun. Elle est constituée de trente et un milliards de transistors et est fabriquée par TSMC sur un processus en sept nanomètres. La puce intègre cinq cent douze composants de sérialisation-désérialisation (SerDes) en PAM4.

L’intérêt d’un tel matériel est multiple, mais se résume à une diminution du nombre de commutateurs nécessaires pour desservir une même quantité de matériel informatique : pour connecter deux cent cinquante-six machines, pour un débit de cent gigabits par seconde chacune maximum, il suffit d’un seul Tomahawk 4. Le matériel actuel ne peut monter, pour de tels débits, qu’à cent vingt-huit ports : il faut donc mettre deux étages de commutateurs pour garantir une connectivité entre toutes ces machines. Le temps de commutation restant équivalent par paquet, la latence d’une communication est divisée par trois. De plus, la consommation énergétique de l’installation est diminuée de septante-cinq pour cent, tout comme le coût d’achat.

Cette puce dispose de fonctionnalités de gestion de la charge, de mise en tampon et de contrôle de la congestion améliorées. La mémoire tampon pour les paquets qui ne peuvent pas être immédiatement transmis sur le lien souhaité est globale à la puce, pour éviter de mettre à disposition de la capacité sur les ports qui n’en ont pas besoin. De plus, cette puce intègre quatre cœurs de calcul ARM à un gigahertz, pour effectuer de l’instrumentation avancée dans le réseau (ces cœurs étant entièrement programmables), au centre des opérations de traitement des paquets Ethernet. La puce intègre aussi nativement une application de suivi statistique, avec une télémétrie intrabande IFA 2.0, une mesure de la qualité des liens et un suivi des pertes de paquet et de la congestion. Pour aller plus loin, Broadcom libère l’API pour ses commutateurs, sous le nom de Broadcom Open Network Switch APIs (OpenNSA, une généralisation de OpenNSL).

Sources : EETimes, WccfTech, The Next Platform.