Les réseaux neuronaux et leur outillage apportent de nouvelles techniques pour la résolution de problèmes inverses, comme l’obtention d’un modèle 3D à partir d’une image. De manière générale, un problème inverse cherche à reconstruire les causes à partir des conséquences, au contraire d’un solveur habituel. Dans le cas particulier de la simulation physique, un solveur traditionnel part d’une situation initiale et de forces appliquées et détermine le mouvement des objets. Au contraire, le problème inverse associé part d’une position finale (comme la position d’un bras robotique) et détermine la manière de l’atteindre.
La simulation de tissus n’est pas forcément une chose aisée, même dans le cas relativement simple des jeux vidéo (on souhaite un rendu réaliste, pas forcément très précis). Parmi les difficultés, on compte la gestion des contacts avec d’autres objets et les collisions, notamment avec le tissu lui-même. Pour la simulation, on tend souvent à découper le bout de tissu à simuler en carrés (par exemple, une grille de seize carrés de côté), entre lesquels on écrit des contraintes pour que cette grille continue de représenter un bout de tissu. Cependant, même dans cet exemple assez simple, on arrive déjà à 289 sommets (seize carrés côte à côte dans chaque dimension, c’est-à-dire dix-sept points de chaque côté), 512 triangles à afficher, 867 variables (une position 3D pour chaque sommet), 140 000 contraintes juste pour prendre en compte les collisions des sommets. Il est impossible de calculer ensuite un gradient en un temps raisonnable pour résoudre un problème inverse…

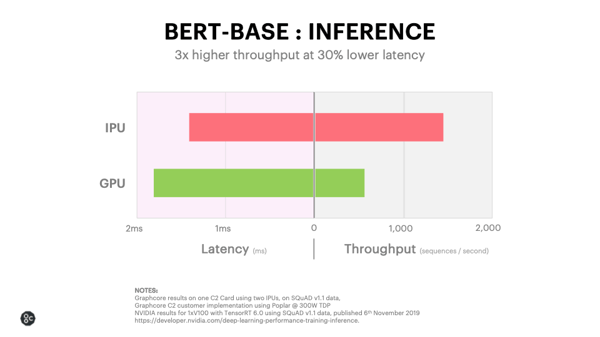
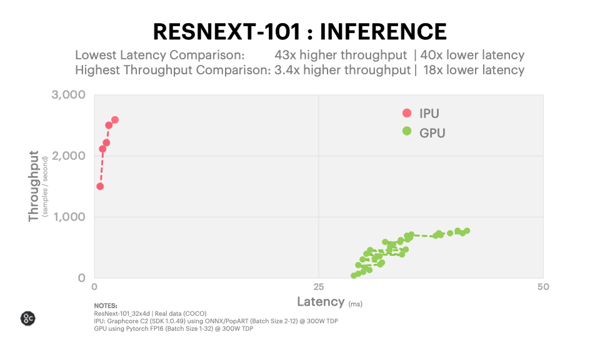
Des chercheurs de l’université du Maryland et d’Intel se sont penchés sur le problème. Ils proposent une nouvelle technique pour déterminer les collisions à l’aide de matrices bien plus creuses (en réalité, un problème d’optimisation quadratique), tout en facilitant le calcul de dérivées (à l’aide d’une décomposition QR). Leur solveur est entièrement dérivable par des algorithmes automatiques (comme Autograd de PyTorch), à l’exception de cette opération de détection des collisions et de calcul des réponses ; ils peuvent en exprimer la dérivée à l’aide du résultat des forces appliquées suite à la collision et de la résolution d’un système linéaire triangulaire. Ils indiquent que, de par leurs expériences, ils peuvent réduire fortement la taille des systèmes linéaires en jeu (d’un facteur dix à vingt) et les temps de calcul (entre soixante et cent trente, bien qu’il peut en théorie monter à cent quatre-vingt-trois).

Parmi leurs expériences numériques, les chercheurs ont testé une estimation des paramètres d’un tissu qui flotte dans le vent. Le modèle physique utilisé nécessite l’estimation de trois paramètres : la densité du tissu, la raideur à l’étirement (à quel point le tissu réagit-il lorsqu’il est étiré ?) et la raideur en torsion (à quel point le tissu peut-il être courbé ou plié ?). Ils prennent en entrée une vidéo du tissu sous l’action du vent et de la gravité et en estiment les paramètres : sur septante-cinq images, les vingt-cinq premières servent à l’estimation et les cinquante dernières à la vérification de la précision d’estimation. En particulier, les chercheurs ne considèrent aucun préentraînement (contrairement à NVIDIA et à sa transformation d’objets 2D en modèles 3D) : ils n’utilisent aucun réseau neuronal, uniquement l’outillage développé pour eux. Le résultat est une meilleure estimation des paramètres du tissu par rapport aux méthodes existantes, sauf dans le cas du pliage.
Source : article. Voir aussi : le code source.